publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
-
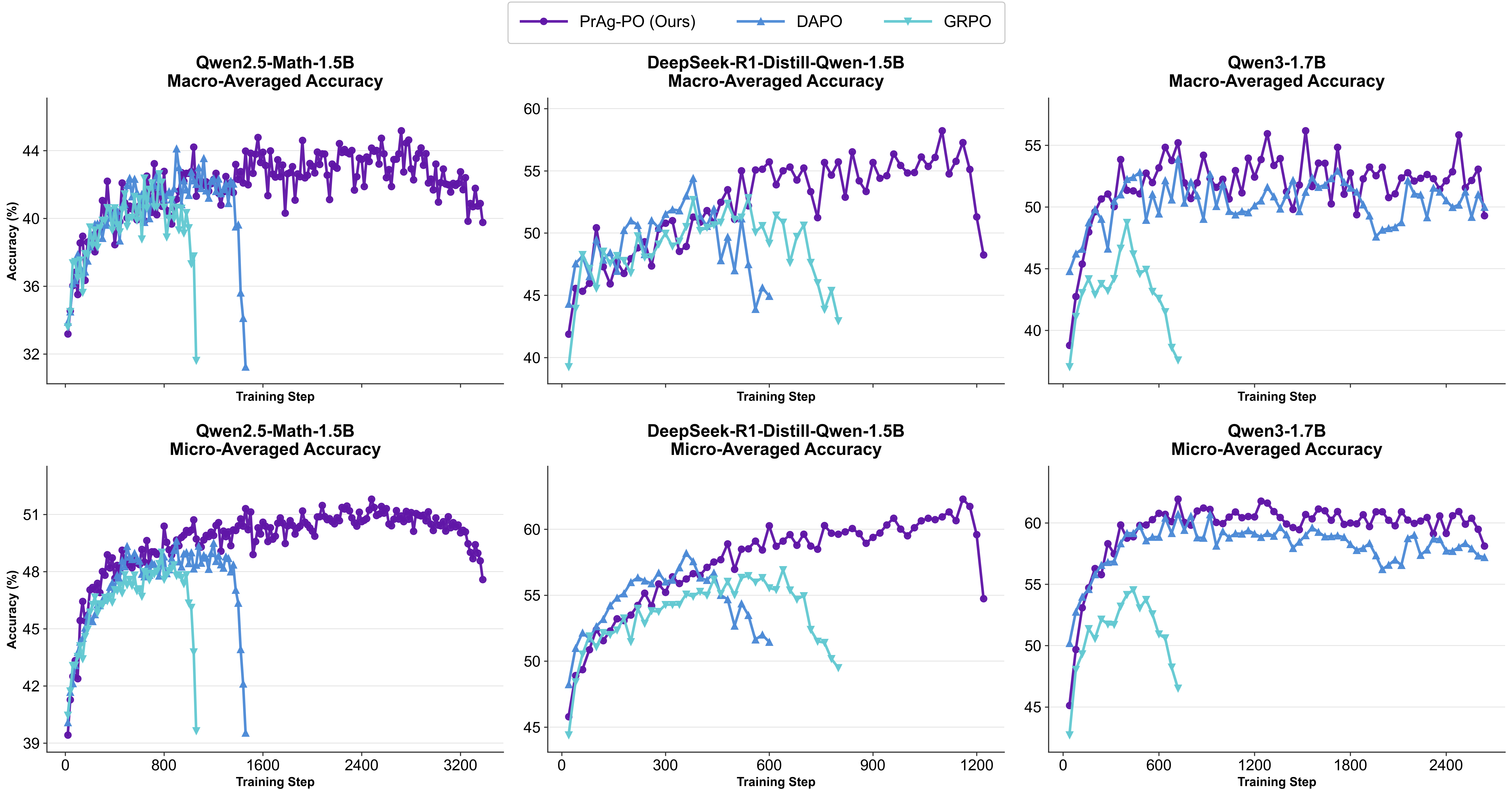 PrAg-PO: Prompt Augmented Policy Optimization for Robust and Diverse Mathematical ReasoningWenquan Lu , Hai Huang , Enqi Liu , and 1 more authorIn arXiv:2602.03190 , 2026
PrAg-PO: Prompt Augmented Policy Optimization for Robust and Diverse Mathematical ReasoningWenquan Lu , Hai Huang , Enqi Liu , and 1 more authorIn arXiv:2602.03190 , 2026Reinforcement learning algorithms such as group-relative policy optimization (GRPO) have shown strong potential for improving the mathematical reasoning capabilities of large language models. While a growing body of work seeks to improve training entropy, rollout diversity, and exploration, most existing methods still train models with a single fixed reasoning prompt or template, which can encourage prompt-specific overfitting and unstable training dynamics. In this work, we introduce Prompt Augmented Policy Optimization (PrAg-PO), a simple policy optimization method that mixes prompt templates with template-specific format rewards during training. By encouraging models to generate reasoning traces under diverse instructions and output formats, PrAg-PO increases rollout diversity and improves robustness. Compared with GRPO and DAPO, PrAg-PO achieves significantly higher reasoning accuracy while mitigating premature training collapse. Empirically, experiments on DeepSeek-R1-Distill-Qwen-1.5B, Qwen2.5-Math-1.5B, and Qwen3-1.7B show that PrAg-PO consistently outperforms strong baselines and achieves competitive performance against recent methods on mathematics benchmarks, using only a fixed MATH Level 3-5 training set of 8.5K problems. The code and model checkpoints are available at https://github.com/wenquanlu/PrAg-PO.

2025
-
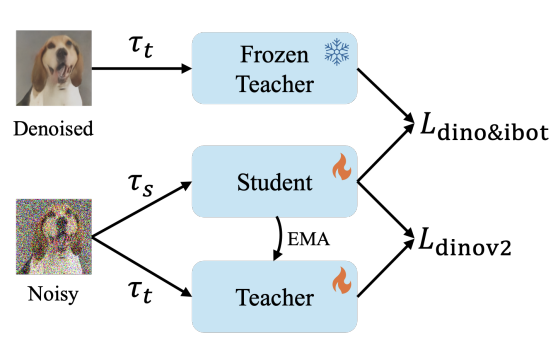 Ditch the Denoiser: Emergence of Noise Robustness in Self-Supervised Learning from Data CurriculumWenquan Lu , Jiaqi Zhang , Hugues Van Assel , and 1 more authorIn Proceedings of the 39th Conference on Neural Information Processing Systems , 2025
Ditch the Denoiser: Emergence of Noise Robustness in Self-Supervised Learning from Data CurriculumWenquan Lu , Jiaqi Zhang , Hugues Van Assel , and 1 more authorIn Proceedings of the 39th Conference on Neural Information Processing Systems , 2025Self-Supervised Learning (SSL) has become a powerful solution to extract rich representations from unlabeled data. Yet, SSL research is mostly focused on clean, curated and high-quality datasets. As a result, applying SSL on noisy data remains a challenge, despite being crucial to applications such as astrophysics, medical imaging, geophysics or finance. In this work, we present a fully self-supervised framework that enables noise-robust representation learning without requiring a denoiser at inference or downstream fine-tuning. Our method first trains an SSL denoiser on noisy data, then uses it to construct a denoised-to-noisy data curriculum (i.e., training first on denoised, then noisy samples) for pretraining a SSL backbone (e.g., DINOv2), combined with a teacher-guided regularization that anchors noisy embeddings to their denoised counterparts. This process encourages the model to internalize noise robustness. Notably, the denoiser can be discarded after pretraining, simplifying deployment. On ImageNet-1k with ViT-B under extreme Gaussian noise (σ=255, SNR = 0.72 dB), our method improves linear probing accuracy by 4.8% over DINOv2, demonstrating that denoiser-free robustness can emerge from noise-aware pretraining. The code is available at https://github.com/wenquanlu/noisy_dinov2.
-
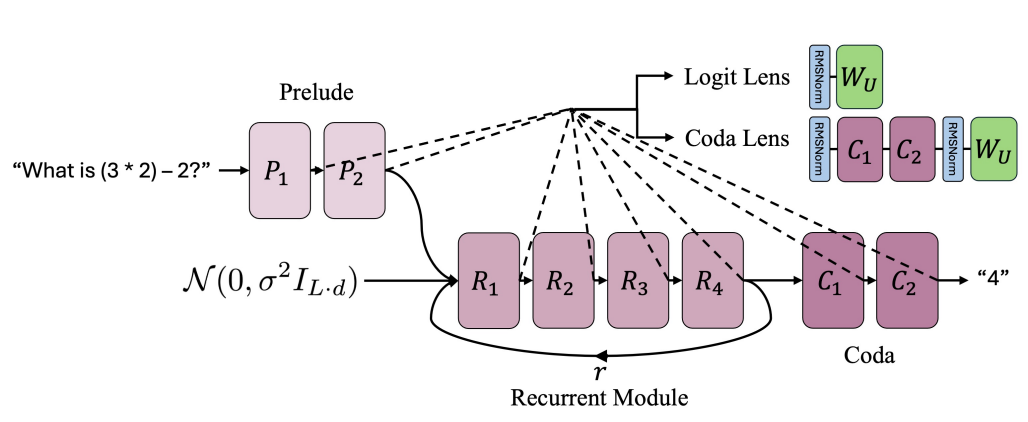 Latent Chain-of-Thought? Decoding the Depth-Recurrent TransformerWenquan Lu , Yuechuan Yang , Kyle Lee , and 2 more authorsIn The First Workshop on the Application of LLM Explainability to Reasoning and Planning @ COLM , 2025
Latent Chain-of-Thought? Decoding the Depth-Recurrent TransformerWenquan Lu , Yuechuan Yang , Kyle Lee , and 2 more authorsIn The First Workshop on the Application of LLM Explainability to Reasoning and Planning @ COLM , 2025Chain-of-thought (CoT) reasoning has enabled transformer-based language models to excel at complex mathematics and multi-step planning. However, in standard decoder-only architectures, these reasoning steps are externalized in natural language, improving interpretability at the cost of efficiency. To capture reasoning that is not easily represented in words, many works have explored recurrent architectures that aim to internalize reasoning in latent space, potentially supporting latent CoT. In this paper, we investigate whether such reasoning structures emerge in Huginn-3.5B, a depth-recurrent Transformer that reuses layers at inference time without increasing parameter count. We examine the model’s internal behavior on arithmetic tasks using a suite of probing techniques including the Logit Lens and Coda Lens. Our findings reveal limited evidence of interpretable latent CoT by tracking rank trajectories of final and intermediate result tokens. Furthermore, we uncover significant probing inconsistencies across recurrent blocks, where the interpretability of hidden states depends heavily on both the layer index and the decoding method. Finally, we empirically show that increasing recurrence depth yields only marginal gains and falls well short of models that explicitly externalize reasoning steps. The code is available at https://github.com/wenquanlu/huginn-latent-cot.


2024
-
 HandRefiner: Refining Malformed Hands in Generated Images by Diffusion-based Conditional InpaintingWenquan Lu , Yufei Xu , Jing Zhang , and 2 more authorsIn Proceedings of the 32nd ACM International Conference on Multimedia , 2024
HandRefiner: Refining Malformed Hands in Generated Images by Diffusion-based Conditional InpaintingWenquan Lu , Yufei Xu , Jing Zhang , and 2 more authorsIn Proceedings of the 32nd ACM International Conference on Multimedia , 2024Diffusion models have achieved remarkable success in generating realistic images but suffer from generating accurate human hands, such as incorrect finger counts or irregular shapes. This difficulty arises from the complex task of learning the physical structure and pose of hands from training images, which involves extensive deformations and occlusions. For correct hand generation, our paper introduces a lightweight post-processing solution called HandRefiner. HandRefiner employs a conditional inpainting approach to rectify malformed hands while leaving other parts of the image untouched. We leverage the hand mesh reconstruction model that consistently adheres to the correct number of fingers and hand shape, while also being capable of fitting the desired hand pose in the generated image. Given a generated failed image due to malformed hands, we utilize ControlNet modules to re-inject such correct hand information. Additionally, we uncover a phase transition phenomenon within ControlNet as we vary the control strength. It enables us to take advantage of more readily available synthetic data without suffering from the domain gap between realistic and synthetic hands. Experiments demonstrate that HandRefiner can significantly improve the generation quality quantitatively and qualitatively. The code is available at https://github.com/wenquanlu/HandRefiner.
